
We Didn't Build an Agent Framework. We Built on One.
When you are a small team building something ambitious, there is a real temptation to write everything yourself, because it feels like control and it feels like an asset; it is, however, almost always a mistake.
The agent framework is the clearest example of this. Every few weeks someone ships a new one, and building your own would mean owning the orchestration loop, the tool-calling protocol, the state persistence, the context-window management, the retry semantics and the streaming, forever — and for a three-person team, "forever" is very much the operative word. Every line you write, in the end, is a line you then have to maintain, instead of a line that maintains itself.
So we made a deliberate choice. The orchestration core of our AI features is not ours: it is open source, it is well-supported, and it is moving faster than we ever could on our own.
The core: DeepAgents, on LangChain, on LangGraph
When an agent runs on our platform, the thing actually driving the loop is LangChain's `create_agent`, wrapped in a small and deliberate middleware stack.
from deepagents.backends import StateBackend
from deepagents.middleware.subagents import SubAgentMiddleware
from deepagents.middleware.patch_tool_calls import PatchToolCallsMiddleware
from langchain.agents import create_agent
from langchain.agents.middleware.summarization import SummarizationMiddleware
from langchain_anthropic.middleware import AnthropicPromptCachingMiddlewareEach one of those imports is a problem that we did not have to solve ourselves:
- DeepAgents gives us the hierarchical pattern, a main agent that dispatches work to subagents, each with its own scoped tools and its own context, and `SubAgentMiddleware` is precisely how an agent delegates instead of drowning. We use the pieces directly rather than the all-in-one constructor — a one-line comment in our compiler actually reads *"we do NOT use `create_deep_agent()`"* — because composing the middleware ourselves gives us exactly the loop we want and nothing that we do not.
- LangChain is the agent loop and the model abstraction. The same code runs against Claude, GPT, Mistral or Gemini, because LangChain has already normalized the differences between them; so we did not write four provider integrations, we wrote one.
- LangGraph is the state layer. Conversations persist to PostgreSQL through its checkpointer, so that a multi-turn agent session survives a worker restart. We did not design a checkpoint format; we simply pointed it at a database.
- `SummarizationMiddleware` keeps long runs inside the context window, and `AnthropicPromptCachingMiddleware` turns Anthropic's prompt caching on, so that we stop paying full price to re-send the same system prompt on every turn. Both are upstream features that we get merely by importing them.
And the tools the agent calls come through `langchain-mcp-adapters`, a `MultiServerMCPClient` that speaks the Model Context Protocol to any compliant server. The protocol is an open standard and the adapter is open source, and so our agents can reach any MCP tool on the internet without us having written a single bespoke integration.
Boring is safe, and hype is prototype land
There is a reflex in this industry to reach for whatever shipped last week, and since the demos are genuinely dazzling, the pull is very real. It is also, however, the surest way to end up with a prototype that you cannot actually put into production. Building a company on a library that emerged a month ago is not bold; it is simply a debt that has not yet been billed to you. One might say that the bleeding edge is, more often than not, exactly where you bleed.
So we pick boring on purpose. Boring, here, means battle-tested, documented and still around in two years; boring is what survives contact with real users and real uptime. Choosing it is not a lack of ambition, but rather the discipline that lets the ambition actually ship.
LangChain and LangGraph are the case in point. We did not touch them in the churny early days, which would have been reckless, and we moved only once they had crossed into stable, post-1.0 territory, the version where the ecosystem had settled into something you can reasonably build a company on. Timing, in other words, is the whole difference between standing on a giant and standing on scaffolding that someone is still in the middle of welding.
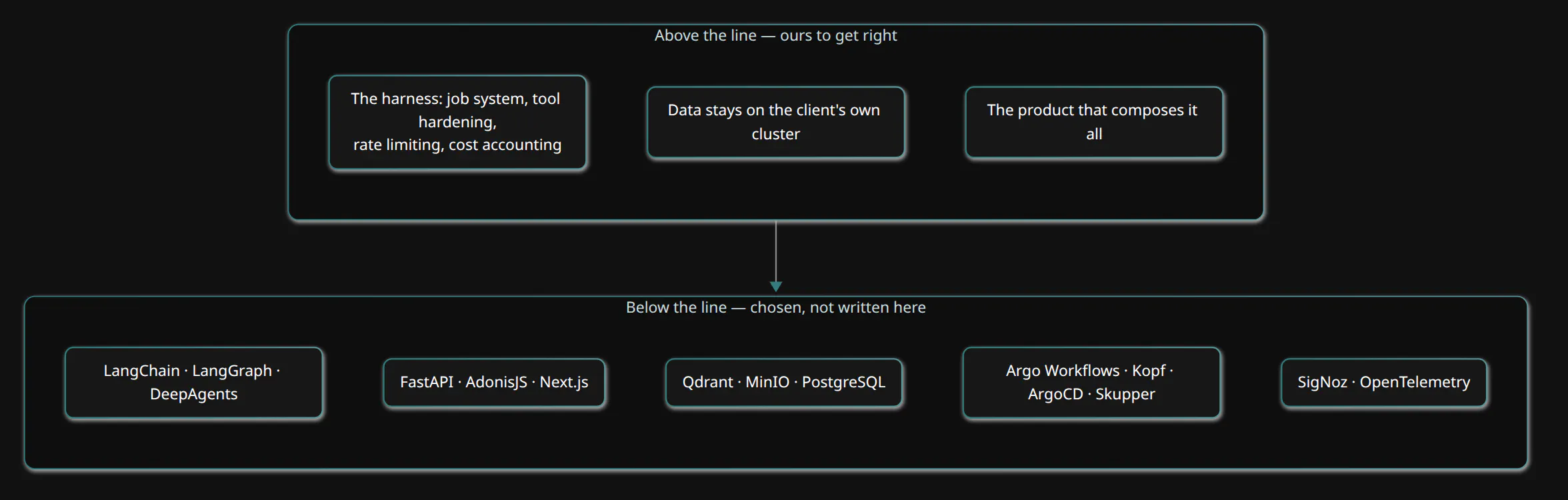
The same instinct runs through the rest of the stack. FastAPI for every Python service; Argo Workflows with the Hera SDK for data pipelines; Kopf for our Kubernetes operators; Qdrant for vector search, MinIO for object storage, Skupper for cross-cluster mTLS networking, ArgoCD for GitOps, and SigNoz with OpenTelemetry for observability; AdonisJS and Next.js on the application side. None of it is especially exciting, and all of it is proven, and each one is a thing we deliberately chose not to build, and just as deliberately chose not to gamble on.
Why this is the harder discipline, and not the lazy one
It is tempting to read "we use open source" as "we took the shortcut," but the opposite is in fact true: standing on these packages is itself a discipline, and it carries a real cost.
You inherit other people's decisions, and you upgrade on someone else's schedule. When a breaking change lands in a 1.x release, you read the changelog and you adapt, and indeed that comment about not using `create_deep_agent()` is exactly that kind of scar tissue, a place where we deliberately chose the lower-level primitive because the convenience wrapper did not quite fit. Depending on a fast-moving library, in short, means staying close to it, reading its source and occasionally working around it.
The trade, however, is straightforward. When LangGraph ships better checkpointing, we get it for free; when Anthropic ships a new caching behavior, the middleware picks it up and our costs drop without us touching the agent at all; and when the MCP ecosystem grows another hundred tool servers, our agents can already call every one of them. We are, in effect, pulled forward by thousands of contributors we will never meet, whereas a framework we had written ourselves would be pulled forward only by the three people who also have to keep the clusters running.
There is an older principle underneath all of this, and it is not really about software at all. The whole reason that science compounds is that you do not re-derive calculus before you publish; you build on what has already been proven, and you add your own piece on top. Open source is precisely that same machine, applied to engineering. Our piece on top is the harness — the job system, the tool hardening, the rate limiting, the cost accounting, and the way the whole thing runs across client clusters where the data never leaves their own infrastructure. That part is genuinely ours, and it is where our effort should go. The agent loop, by contrast, is a solved problem maintained by a community, and re-solving it would have been the vanity, not the rigor.
The part we do own
Open source, in the end, draws a rather clean line through the system. Below the line sit the agent loop, the model abstraction, the state store, the web framework, the queue and the vector database, all of them community-maintained, all of them chosen, and none of them written here. Above the line sit the things that are genuinely ours to get right: the harness that lets an agent survive a bad API, the architecture that keeps a client's data on the client's own cluster, and the product that lets someone compose all of it without ever touching any of it.
We also give a good deal of it back. Our SRE agent is open, and so is our AdonisJS tooling (the controller validator and the migration squasher); it is, in a sense, the same loop we benefit from, finally closing.
The best code, then, is the code you never had to write, and the second best is the small, sharp layer that you did write on top of it — the part that is actually, genuinely yours.



