
2026 Is the Year of the Harness. We Built a Different Kind.
The model itself has become the easy part. You can call Claude or GPT in three lines of code, and so the real difficulty, the part that never quite makes it into the demo, lies entirely in everything that surrounds the model: the layer that gives it tools, that runs it on a schedule or off a queue or in reaction to some external event, that retries when a tool times out, that caps how fast it hammers an external API, that keeps the secrets out of the logs and tells you afterwards what the whole thing actually cost. This scaffolding has a name, the harness, and it is where almost all of the real engineering of an AI feature actually lives.
If 2026 has a theme, it is that the harness *became* the product. Claude Code is a harness, and an exceptional one, for writing software; OpenCode is another; even n8n, stretched far enough, is one too. The idea, in other words, is not ours, and the race to build a good one is already crowded. I am not here to claim that we invented it.
What we did build is a different kind of harness, however, and that difference is rather the whole point. Most harnesses wrap a single use case, whether coding or chat or automation, whereas ours is a production substrate that fuses together things which normally live in five separate tools: deterministic pipelines, deep agents, retrieval (read: RAG), MCP tool servers, and the observability to actually see what any of it did. It is one stack, in other words, instead of five integrations you have to maintain yourself. And underneath all of it sits one idea that I do think is genuinely ours, namely that a pipeline and an agent can be built out of the *same* pieces. I will come back to it.
Lacking that, most teams end up building the glue by hand, every time, and badly: a retry loop here, a rate limiter there, a tool integration that works perfectly well until the upstream returns a 429 and the entire run dies with it.
What a harness actually has to do
If you strip away the marketing, an AI agent in production is really doing a small number of rather unglamorous things, over and over again:
- It needs tools — that is, ways to act on the world, and not merely to talk about it.
- It needs to run somewhere reliable, triggered by a job or an event or a user request, on infrastructure that does not simply fall over.
- It needs to survive failure: a tool times out, a server returns garbage, a rate limit trips, and through all of it the agent should degrade rather than die.
- It needs guardrails — the secrets kept out of the logs, the external APIs not flooded, a ceiling on how long any single run is allowed to burn.
- It needs to be observable, so that you can answer what it called, how many tokens it spent, what it cost and where the time actually went.
None of that is the model. All of it is the harness. And once you have built it well a single time, you never again want to build it from scratch.
The workers system
Our platform runs on a job-processing system we call workers, and the unit of work is a node, which is simply a Python class with a typed input and a typed output. There is nothing more exotic to it than that.
class BaseNode:
def init(
self,
name: str,
type: str,
description: str,
input_schema: type[BaseModel], # a Pydantic model
output_schema: type[BaseModel], # a Pydantic model
semaphore_limit: int = 10, # how many run concurrently
retry_config: RetryConfig | None = None,
...
):That is the whole contract. You declare what goes in, what comes out, how concurrent it is allowed to be and how it retries. The schemas are Pydantic, which means that validation happens before your code ever runs, rather than three function calls deep, where a bad type quietly turns into a 2am incident.
You then wire those nodes into a graph. A job arrives on an SQS queue, the runner compiles the nodes and edges into a directed acyclic graph, sorts it topologically and executes it, running in parallel everything that *can* run in parallel and bounding each node by its own semaphore. Downstream nodes read upstream outputs through a small template syntax, `{{ @someNodeId.field }}`. The retry logic, the concurrency caps, the per-job context, the cost accounting, the cleanup: the framework owns all of it.

Adding a new capability is therefore three steps. You write a class with an input and an output schema, you implement `process()`, and you register it in one mapping. There is no config file to edit and no deployment ritual to perform, and the input schema drives the UI form on its own. The framework, in other words, is the harness; you simply declare the pieces.
There are already more than thirty node types in that mapping: vector search, reranking, OCR, document read and write, HTTP, keyword search. And, of course, the one this whole essay is really about, an agent.
Dropping an agent into the graph
One of those node types is a deep agent, and you place it in the graph like any other node. An agent, however, is only ever as useful as the tools it can reach, and this is where the harness earns its keep, twice over.
A deep agent is just another node — a system prompt, a typed input, a typed output — configured in the same editor as everything else.
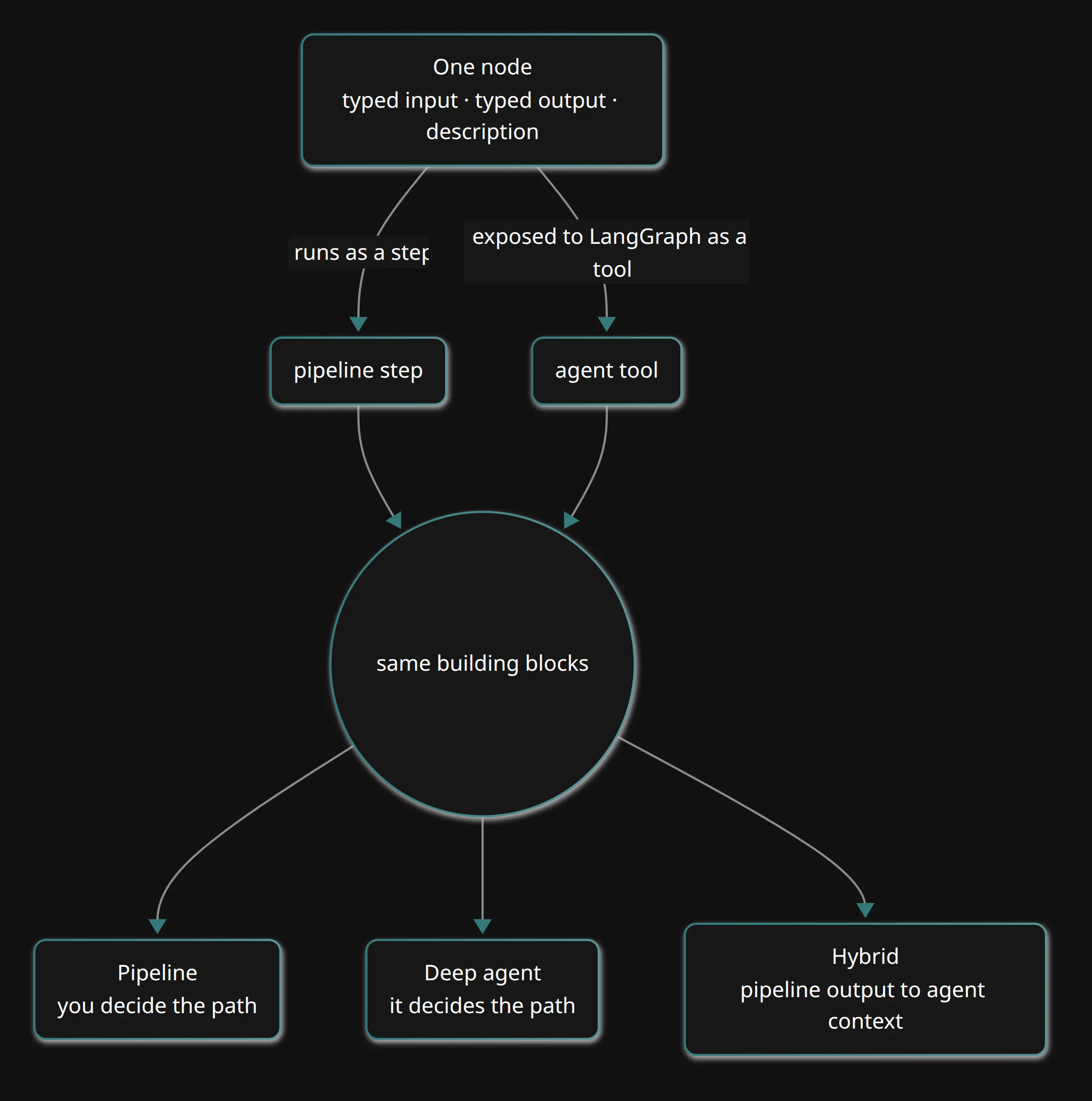
The first thing to understand is that every node is, in fact, two things at the same time, and this is the part that most people tend to miss. The very same node is both a step in a workflow pipeline and a tool that an agent can call; it is not a node accompanied by some separate tool adapter, but rather a single object that happens to have two natures.
The reason this works is the rather boring discipline from the previous section. Every node carries a clean Pydantic contract — a typed input, a typed output, a description and a cost — and that contract is all LangGraph needs in order to expose the node as a tool. So we hand it over natively: the input schema *becomes* the tool's argument schema, and the description and cost *become* the tool's description. There is no second definition, no adapter to maintain and no drift between "the pipeline version" and "the agent version." The agent calls a node in exactly the way the runner does, with the same validation, the same retries and the same concurrency caps.
That dual nature is what gives you three different ways to build, all from the same set of nodes:
- A pipeline. A deterministic DAG, where you decide the path and it runs the same way every single time. Predictable, auditable and cheap.
- A deep agent with the power of a pipeline. Here you hand the agent the nodes as tools and let *it* decide the path at runtime: it calls vector search, reads the result, decides to OCR a document and then reranks. The agent improvises, but with the very same building blocks the pipeline uses.
- A hybrid. Here a deterministic pipeline runs first, and its output flows into the context of a deep agent. The fixed work you want guaranteed runs as a pipeline, while the open-ended reasoning runs as an agent, primed with whatever the pipeline produced.
You write a capability once, as a node, and it then serves all three.
The second way the harness earns its keep is that any MCP server can join in, by URL. MCP, the Model Context Protocol, is the emerging standard for exposing tools to a model over HTTP. You point a node at a server URL, optionally filter which of its tools it may use, and those external tools join the same toolbox as the native ones. To the agent, a vector search you wrote yourself and a legal database on the far side of the internet are the same kind of thing: a typed tool that it can call.
The MCP side is also where the harness does the unglamorous work that you would otherwise spend a month getting right:
- The tool schemas are loaded once and then cached, for five minutes per server. The MCP handshake is two network round-trips, and performing it on every subagent on every request would add seconds of latency for nothing; so we do not.
- Every tool is hardened before the agent ever sees it. If a server returns an empty result, the agent receives a clean "no results" message and decides what to do next, rather than crashing; and if a server errors, times out or returns malformed data, the agent receives a short, sanitized message instead of a stack trace.
- Secrets never reach the model. Bearer tokens, JWTs, API tokens and full URLs are all stripped out of any error string before it enters the agent's context, so the model sees `Bearer [REDACTED]` and not your credentials.
- External APIs are rate-limited per server. Some upstreams have hard quotas, so the harness throttles requests to each one independently, which keeps a chatty agent from getting the whole integration banned.
A single tool failing, therefore, does not abort the run, and that one property is most of the difference between a demo and an actual system.
The legal example: LegalDataSpace
Here is the harness doing real work, at scale, inside someone else's product.
LegalDataSpace, the European leader in legal connection, is building its platform on top of ours. This is not a single agent calling a single database; it is a full agentic marketplace.
The legal field is drowning in text, and it is deeply fragmented. French labour law lives in one place, collective agreements in another, the official journal in a third, case law in a fourth, EU law in a fifth, and trademarks and the business registry in others again. A real legal question — say, what makes a non-compete clause valid — does not map onto a single source; it spans a dozen of them.
So LDS did not build one agent. They built a marketplace of specialized ones, each an expert in a single source and each running its own multi-step workflow: a Code du travail agent, a Légifrance agent, a Judilibre case-law agent, an EUR-Lex agent, a CNIL data-protection agent, an INPI trademark agent, a business-registry agent, a cross-source semantic-search agent over 2.2 million court decisions, and more besides. An orchestrating agent then reads the question and routes it to the right specialist, knowing, for instance, that a collective-agreement question belongs to one agent while a social-security question belongs to another. Specialists running complex workflows, composed under a router: this is exactly the hierarchical agent-and-subagent pattern that the harness was built to run.
Every one of those specialists is the very same construction from the section above, with the external legal sources arriving as MCP tools and sitting in the same toolbox as the native nodes. A specialist can search its source, rerank what comes back, extract text from an uploaded contract and run a vector search over the client's own documents, calling external tools and native nodes interchangeably. The agent decides which to reach for, and the harness makes them look identical.
And it is precisely the unglamorous parts that make a *marketplace* of these viable, rather than merely a demo of one. Each legal source is metered, so the harness throttles each one independently, to roughly one request per second with a small burst on the rate-limited ones, configured per source and with no code change. When a search returns nothing, the source answers in French, `aucun résultat`, and the harness reads that, alongside the English markers, as an empty result rather than an error, so the agent simply tries another query. When a source has a bad moment, the agent sees a clean message and moves on, instead of dying mid-answer. Multiply all of that across a dozen specialists answering real questions all day, and "a single tool failure does not abort the run" stops being a nice sentence and becomes, quite literally, the reason the marketplace stays up.
None of this, however, is specific to law. It is the same harness that runs our own internal research agents against our own MCP servers: the dataset catalogue, a bibliometric search tool over the hundreds of millions of research products indexed by OpenAIRE, and a connector into the French national library's digital archive, Gallica. Different domain, same harness. We dogfood the exact thing that LegalDataSpace builds on.
Inspired by n8n, built for production
The visual-node-graph idea is not ours either. n8n popularized it, and n8n is genuinely good at what it does, so we borrowed the inspiration twice over, once for the engine and once for the interface. There is a no-code visual editor in which you drag nodes onto a canvas and connect them, with the same approachable feel that made n8n click for so many people.
The no-code editor — the same canvas that runs in production. Here a deep agent dispatches to a subagent, which in turn reaches two MCP servers as tools.
The difference lies in what sits underneath that canvas. n8n optimizes for the first ten minutes — drag, drop, connect, run — which is exactly why it is a wonderful prototyping tool, and also exactly why it tends to stay one. The moment you actually need a typed contract on every step, an agent and a pipeline sharing the same building blocks, per-source rate limits, secret redaction and failure that degrades rather than cascades, the easy tool runs out of road.
We made ours more configurable, and I will be honest about the cost of that: more power is simply more to understand. The Pydantic contract on every node, the three execution modes, the hybrid — there is more depth here than dragging a box onto a canvas, and it would be dishonest to pretend otherwise. The visual editor is how we keep the on-ramp gentle, while the depth is what waits for you once you outgrow the easy path; you start simple and grow into the power, rather than hitting a ceiling.
That depth is, in the end, why a company like LegalDataSpace builds its product on us rather than on a prototyping tool. The configurability that creates the learning curve is the very same configurability that makes the next ten thousand hours possible. Typed contracts are what let a node be both a pipeline step and an agent tool without drifting apart, and the hardening is what keeps a marketplace of a dozen agents running all day long. Production, in other words, is not a toy that grew up. It is a different thing altogether, built for a different time horizon.
What you no longer have to build
That, ultimately, is the point of a harness: the list of things you no longer have to write yourself.
You do not write the retry-with-backoff loop, nor the rate limiter, nor the token redactor, the schema cache, the concurrency bounding, the cost meter, the queue consumer or the DAG executor. You write a node — an input schema, an output schema and the logic in between — and you connect an agent to a tool.
The model was always going to become a commodity, since anyone can call one. The durable engineering, the part that actually decides whether your AI feature survives contact with a real API on a bad day, is the harness around it.
We built ours so that we would never have to build it twice, and then we made it the thing that other people build *on*.



