
Agents Don't Read APIs. They Read Meaning.
For the past forty years we have written our APIs for programs, and a program never really needed to understand an endpoint; it needed the exact byte layout, that is, which field is a string, which one an integer, where the authentication header goes and what each status code means. The contract was, in essence, a syntactic one. Agents, however, have quietly broken that assumption, and it seems that most people have not yet caught up with what it actually means.
An agent does not operate in byte layouts at all. It operates in language, in tokens, in meaning. When a Large Language Model decides to call a tool, it is not parsing your OpenAPI spec (read: the rigid machine contract); it is reading a short piece of natural language, deciding whether this particular tool fits the situation, and inferring how to use it from what the words actually say. The interface an agent consumes is, therefore, not syntactic but semantic.
That, in the end, is the whole reason MCP exists, and it is also why the claim that "MCP is just a wrapper around your API" misses the point so completely.
What MCP actually is
The Model Context Protocol reframes a capability into three things that an agent can hold in its head at once: an input, an output and a description. That is the unit. It is not a sprawling reference page nor a 200-line spec, but rather a compact semantic object that the agent loads directly into its context and reasons over.
The split matters more than it first appears. Old-style API documentation was written for a human who would read it once, carefully, and then go off and write code, and so it tends to be thorough and rather verbose: pages of prose, every edge case, every field. An agent cannot really use that, however, because every token of description it loads is a token of context it has to spend, and a wall of reference docs is at once too long and written in the wrong register. The opposite extreme, though, the bare one-liner that an OpenAPI spec usually carries, something like "Search the catalogue via SRU," is far too little, since it tells the agent nothing about when it should reach for this tool, what the parameters actually mean, what comes back or what to watch out for.
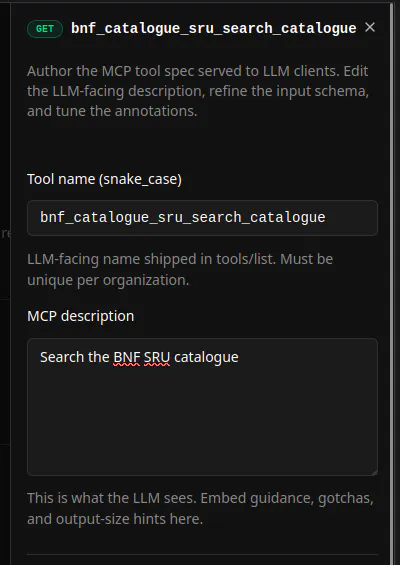
A real auto-generated tool. The whole of what the agent gets to read: "Search the BNF SRU catalogue." That is the problem, in one screenshot.
The art of building an MCP tool, therefore, lies in finding the middle: the smallest piece of language that lets an agent wield your capability correctly, in its own verbiage. That is not documentation. It is a semantic feature, a designed surface written for a reader that thinks in meaning, and getting it right is genuinely hard. It is, in fact, the real work of putting an API in front of an agent.
We learned this the hard way, by hand
We did not arrive at this by theorizing. We built MCP servers, a great many of them: a connector to our own data clusters, a bibliometric tool over the hundreds of millions of research products indexed by OpenAIRE, a bridge into the French national library's digital archive, Gallica, and the library of specialized legal connectors behind LegalDataSpace, each one fronting a different French or European legal source.
Every one of them taught the same lesson from a slightly different angle. A tool with a beautiful schema and a lazy description gets called wrong. A description that brags about a capability the endpoint does not actually have sends the agent straight down a dead end. A tool that fails to warn you it returns `success: true` even on failure quietly poisons everything downstream of it. The difference between a tool an agent uses well and one it fumbles, in other words, is almost never the code; it is the semantics.
So, over time, we accumulated a craft: what a good tool description names, how it states its return shape, when it warns and how long it ought to be.
And then we noticed something rather important about *who* should be doing this work in the first place. A human can certainly write a semantic layer, and indeed we did, by hand, for years. But the reader here is an LLM, and it seems to us that the best author for an LLM reader is another LLM. A person writes documentation the way a person would want to read it: narrative, exhaustive, reassuring. A model, however, needs it written the way a model reads it, in the tokens, the framing and the implicit weightings that match its own internal logic. You write for a human as a human; you should write for an LLM as an LLM. The two are simply not the same register, and the gap between them is exactly where hand-written and auto-generated tools both tend to fail.
That, in turn, reframes the whole problem. The point is not merely to "have a model write the descriptions," since anyone can prompt that and get confident nonsense back. The real science of MCP creation lies in how you make the model do this job *well*: rigorously, from evidence, and without inventing capabilities the API does not actually have. That is a systems problem rather than a prompt, and so we built the system, out of our own Alien Agents.
Automating the craft with frontier models
Bring an API to Alien and we will generate the MCP tools from it automatically, one tool per endpoint, typed and callable. That is the mechanical half, and on its own it gives you tools with the same lazy descriptions that any auto-generation would.
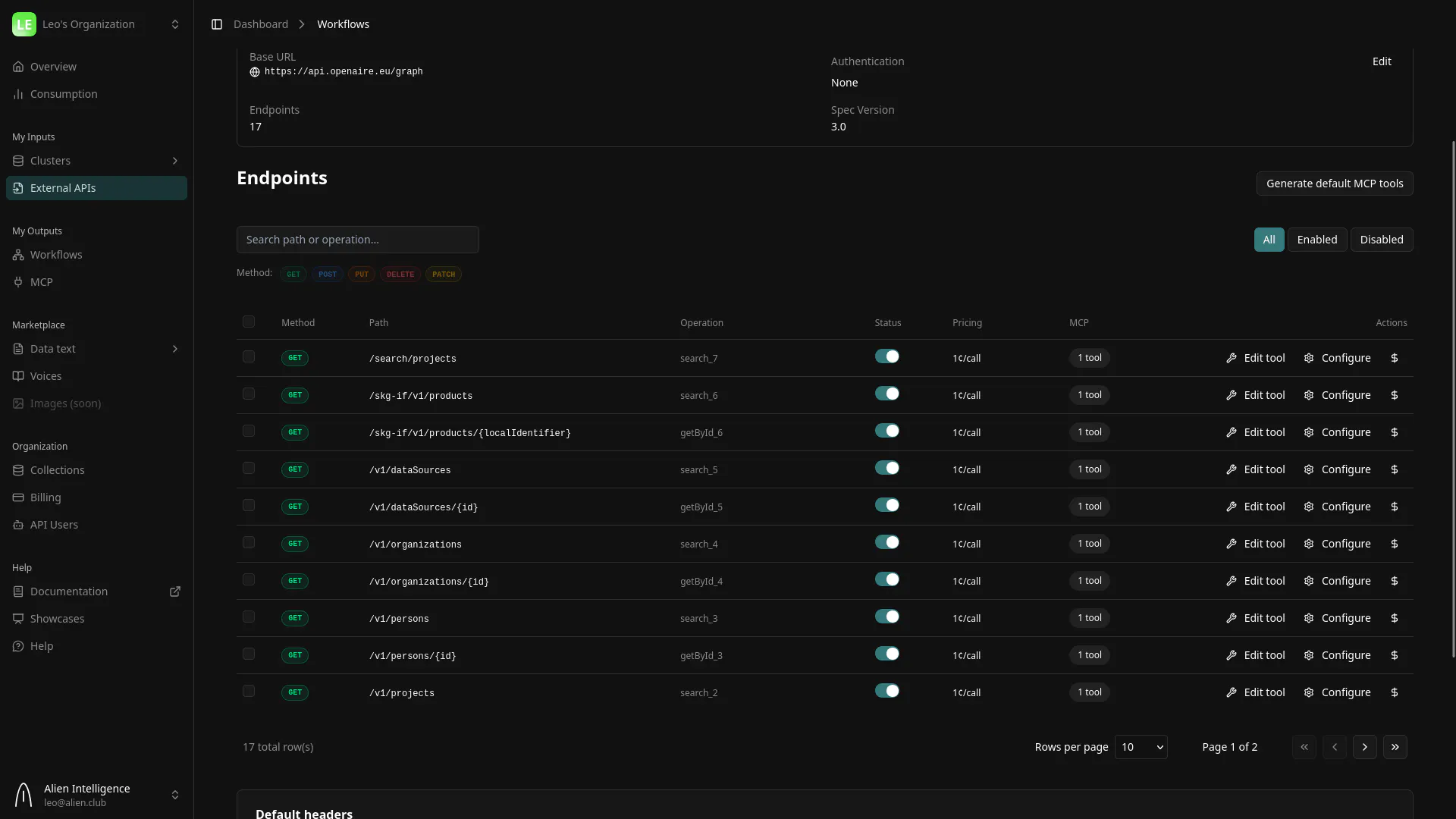
Point Alien at an API — here, OpenAIRE — and every endpoint becomes a typed MCP tool. The mechanical half, done in a click.
The interesting half is what happens next, and how we built it comes from somewhere that, given where I come from, I genuinely cannot unsee. I spent a decade in computational biology before all of this, and there is one idea from that world that I trust more than any architecture diagram: nothing good ever gets designed in a single shot. Nature does not design; it varies and it selects. A population throws up variants, reality then kills the ones that do not hold up, and you run that loop across generations until what survives is something no designer could ever have written correctly on the first attempt.
A single model told to "improve these descriptions" is, in a sense, the very opposite of that. It is a lone designer with no feedback, inventing improvements just as confidently as it surfaces real ones, and with no way of telling the two apart. So we did not build one model. We built a small evolutionary loop instead, a population of Alien Agents with deliberately opposing jobs, all working the semantics against the real API:
- An auditor serves as the source of variation. It connects to the freshly generated tools and tests each one *by actually calling it*, one to three real calls, observing the real response, and then proposes a rewrite. It works under strict evidence rules, however, because a model that is asked to find problems will happily invent them: it may not claim a limit it never probed, nor a behavior it never observed. Variation, in other words, but grounded in what the API genuinely did.
- A critic serves as the selection pressure. It has no tools at all, since it only reads, and it accepts, edits or rejects each proposal in turn. It is the one that kills the unverified claim, the merely cosmetic reshuffle, the warning deleted for no good reason. The auditor's job is to propose, and the critic's job is to doubt; most variants do not survive it, which is rather the point.
- An orchestrator runs the generations. It applies only what the critic has approved, re-tests, and loops until the population stops improving, that is, until the catalogue converges, with hard caps in place so that it can never run away.

That, then, is the *why*, and not simply "we chained three prompts together." We chose variation-and-selection because it is the only process I know of that reliably produces good design without requiring anyone to be right up front, the very same algorithm that wrote every genome, aimed now at a paragraph of tool documentation. It is the craft we once did by hand, written by LLMs for LLMs, and run by the same Alien Agents that power everything else on the platform.
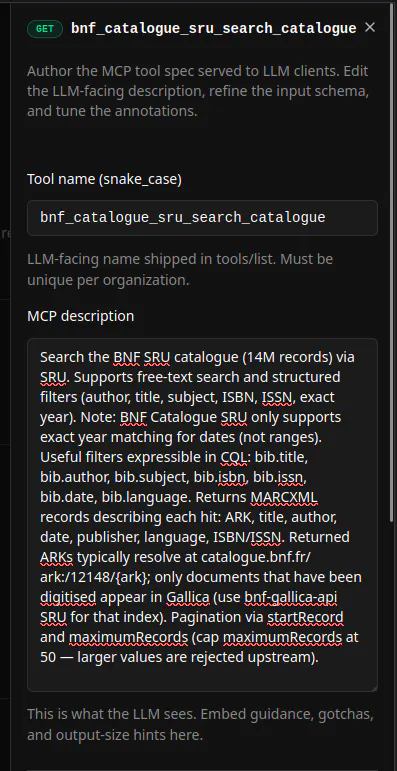
The same tool, after the loop: the parameters, the return shape, the 50-record cap ("larger values are rejected upstream"), and the Gallica gotcha — everything an agent needs, and nothing it has to guess.
It is also honest about its own edges. It improves the semantics; it does not pretend to fix your API. When it finds a genuine server bug, that bug is logged and described as a warning rather than quietly papered over. And a run costs a dollar or two and a few minutes, which the interface tells you plainly before you start.
The point: bring your API, sell your data
Here, finally, is why any of this should matter to you, if you happen to own an API or a dataset.
The agent economy is going to consume data through MCP. The companies whose data is reachable, and *correctly* reachable, in language an agent can actually use, will be part of that economy, whereas the ones whose data sits behind a syntactic API that no agent can wield will simply not be. The gap between those two states is, precisely, the semantic layer that this whole piece has been about.
So bring your API layer to Alien. We turn it into agent-ready MCP tooling, we use frontier models to keep its semantics good and true as the underlying API changes, and we put the whole thing behind our observability and monetization layer. You see every single call — who invoked what, when, and how it performed — and you charge for it: your data access, metered and monetized, sold into the agent economy through a surface that agents can actually consume. Your data, on your terms, with the semantic work already done for you.
APIs spoke to programs for forty years. The next thing reaching for your data, however, speaks in meaning. The work, in the end, is translation, and we have made it into something you can run on your own API in an afternoon, and then get paid for.



